
こんにちは、@yshr10icです。
以下のツイートをしてからだいぶ経ってしまいましたが、そろそろ重い腰を上げてやってみたいと思います。
最近コンペの実験管理Notionでやってるけど、そろそろPythonで自動化するか
— yshr10ic (@yshr_10ic) September 30, 2021
対象読者
- Notionで実験管理をしているがまだ自動化できていない方
- これからNotionで実験管理をしようと思っている方
- Notionで実験管理がどこまでできるか気になる方
免責事項
- 作成したコードはGoogle Colaboratory上で動作確認したものです
- 軽いノリで始めたことなのであまり深いところまでは確認できていません。クラス設計も適当です
- コード例を紹介しますが、エラーハンドリングなどは一切してませんので予めご了承ください
- 正直他の実験管理ツールに比べるとNotionだとできることが限られます。あまり期待しないでください笑
- もし追加で確認して欲しいことなどあればTwitterでコメントいただければ暇なときに確認します。お気軽にコメントください
久しぶりに結構しっかり書いたので、よかったら読んでください!
— yshr10ic (@yshr_10ic) January 10, 2022
もし追加で検証して欲しいことなどあれば、コメントしてもらえると嬉しいです!
データ分析コンペの実験管理を自動的にNotionに連携するhttps://t.co/kTs8aQY1UB
Notionとは
本記事を読んでいる方は既にご存知だとは思いますが。
Notionは一言で表すのは難しいくらい多機能なツールですが、Googleで検索するとタスク管理、ドキュメント管理、データベース、万能ツールといった表現がよく使われています。EvernoteやScrapboxが似たようなサービスとして挙げられます。
私自身もタスク管理や読んだ本の記録、購入した物の管理、そして今回紹介するデータ分析コンペの実験管理をNotionで管理しています。自分好みにカスタマイズでき、非常に便利なツールとなっています。
データ分析コンペの実験管理
KaggleやSIGNATEといったデータ分析コンペに参加する際には、各実験でどのモデルを使ったのか、そのときのハイパーパラメータは何だったのか、評価値はいくつだったのかを実験管理としてまとめています。
私の場合は、個人で参加するときはNotionを、チームで参加するときはGoogle Spreadsheetをよく使っています。
実験管理用のツール比較については、ふぁむたろうさんがQiitaでまとめてくださっているので、こちらをご参照ください。

Notion側の設定
それではここからデータ分析コンペの実験管理をNotionに連携するために、どうすればよいのか説明していきます。まずはNotion側の設定からです。
実験管理まとめページの作成
Notionにすべての実験管理をまとめるためのページを作成します。一旦私の場合は、「コンペ実験管理」というページを作成し、table databaseで作成しました。

以下のカラム以外にもコンペの終了日や最終的な順位、メダルなどを管理してもよいかもしれません。
| カラム名 | プロパティ | 説明 | 例 |
|---|---|---|---|
| Name | Title | 参加しているコンペの名前 | Jigsawコンペ |
| WebSite | Select | コンペサイト名 | Kaggle/SIGNATE/ProbSpace |
| URL | URL | コンペのURL | – |
| Type | Select | コンペの種別 | Tabular/Image/NLP |
NotionのAPIを使えるようにするためには、integrationを追加する必要があります。
Integrationの追加
以下のサイトにアクセスし、Integrationを作成します。Integrationを作成したら、画面にある「Internal Integration Token」をコピーしておきましょう。後で使います。

作成したIntegrationにデータベースの編集権限を追加する
続いて、作成したIntegrationにデータベースの編集権限を追加します。
ページ上部にある「Share」をクリックし、「Invite」横のテキストボックスをクリックします。そうすると先ほど作成したIntegrationの名前が表示されるので、それを追加してください。これでAPI経由でこのページを編集することができるようになります。

コンペページの作成
今回はテストコンペというページを作りました。

今回自動化対象とするのは実験管理というinline databaseとなります。「Base Exp」というカラムを作っておくことで、ベースとなる実験の評価値を参照したり、スコアが上がったのか下がったのかを計算することができるようになります。
| カラム名 | プロパティ | 説明 | 例 |
|---|---|---|---|
| Submit | Checkbox | サブミットしたかどうか | – |
| Exp | Title | 実験管理名 | Exp002 |
| Date | Date | 実験日 | 2022/01/10 |
| Base Exp | Relation | ベースとしたExp | Exp001 |
| CV | Number | ローカルCVの値 | – |
| Public LB | Number | Public LBの値 | – |
| Model Name | Select | モデル名 | LGBM |
| Preprocessing | Multi Select | 前処理名 | Normalization、Standardization |
| Memo | Rich Text | メモ | – |
この「実験管理」テーブルをAPI経由で編集するために、idを控えておく必要があります。実験管理テーブルの上にマウスを持っていくと、右側にいくつかアイコンが出てくるので、「↔︎」の「Open as page」をクリックし、ページとして開いてください。
そうするとURLが「https://www.notion.so/<ユーザ名>/<データベースID>?v=<ビューID>」となっていますので、ユーザ名の/(スラッシュ)の後から「?v=」の前までをコピーしておいてください。

今回の自動化対象外ですが、「実装アイデア」というinline databaseを作ることによって、今後実装しようとしているアイデアを同じページで管理することができます。これ以外にも他の人が書いたディスカッションや参考となる論文などを管理するのもよいかもしれません。
| カラム名 | プロパティ | 説明 | 例 |
|---|---|---|---|
| Impl | Checkbox | 実装したかどうか | – |
| Idea | Title | 実装アイデア | ××モデルを実装する |
| Tags | Multi Select | 実装アイデアの種別 | Model |
これでNotion側の設定は完了です。
連携用コード
Google Driveとの連携
Notionとの連携事態には必要ありませんが、サンプルでCSVファイル読み込むために使います。
# mount drive
from google.colab import drive
drive.mount('/content/drive')
# change directory
import os os.chdir('/content/drive/My Drive/Colab Notebooks/notion/')
print(os.getcwd())ライブラリのインポート
必要なライブラリをインポートします。
import warnings
warnings.simplefilter('ignore')
# Notionとの連携に使用
import datetime
import json
from pprint import pprint
import requests
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_scoreConfigクラス
Notion連携用の情報をConfigクラスとして持っておきます。notion_tokenには先ほどコピーしておいたIntegrationのトークンを、database_idには先ほどコピーしておいた実験管理テーブルのデータベースIDを設定してください。
class Config:
notion_token = '<YOUR API TOEKN>'
notion_endpoint = 'https://api.notion.com/v1'
database_id = '<YOUR DATABASE ID>'
headers = {
'Authorization': f'Bearer {notion_token}',
'Content-Type': 'application/json',
'Notion-Version': '2021-08-16'
}Configクラスの情報を使ってNotionがデータを取得できるか試してみます。
response = requests.request('GET', url=f'{Config.notion_endpoint}/databases/{Config.database_id}', headers=Config.headers)
pprint(response.json())
以下のような結果が返ってくれば成功です!

PropertyTypeクラス
実験管理テーブルの各カラムにはtitleやnumberなどプロパティが設定されています。APIで情報を連携する際には、プロパティに応じて送る情報が少し異なるため、判別用のクラスを作成しておきます。以下のPropertyType以外にも設定できるプロパティはあるのですが、今回は使用しないため設定していません。
class PropertyType:
TITLE = 'title'
RICH_TEXT = 'rich_text'
NUMBER = 'number'
DATE = 'date'
CHECKBOX = 'checkbox'
SELECT = 'select'
MULTI_SELECT = 'multi_select'
RELATION = 'relation'各カラムがどのプロパティなのか、先ほど試しに取得したresponseをもとに辞書を作っておきます。
properties = {}
for k, v in response.json()['properties'].items():
properties[k] = v['type']
pprint(properties)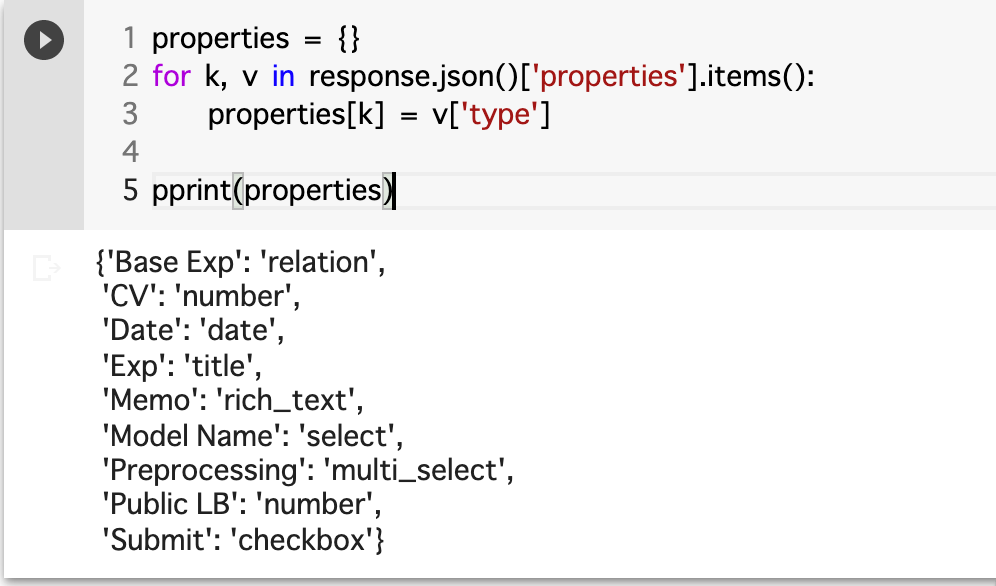
Cellクラス
連携する情報はこのCellクラスをインスタンス化して利用します。少しコードが長いので、それぞれのメソッドが何をしているのかを簡単にまとめます。
| メソッド名 | 説明 |
|---|---|
| __init__ | 初期化メソッド |
| to_dict | NotionのAPI連携用に必要な情報を辞書に変換する。プロパティごとに辞書の形は異なる |
| _to_dict_XX | プロパティごとに必要な情報を辞書に変換する。共有したメソッドとしている場合もある(その場合のメソッド名は適当) |
| get_multi_select_values | multi_selectの場合は、選択肢が一つが複数の場合で辞書に渡す形が異なるため、渡された値の型によって辞書の形を変更している |
| get_page_id | relationの場合は、関連付けをしたいレコードのIDが必要となるため、API経由でIDを取得している |
class Cell:
def __init__(self, key, properties, values):
self.key = key
self.property_type = properties[self.key]
self.values = values
def to_dict(self):
if self.property_type in [PropertyType.TITLE, PropertyType.RICH_TEXT]:
return self._to_dict_text()
elif self.property_type == PropertyType.DATE:
return self._to_dict_pattern2('start')
elif self.property_type == PropertyType.NUMBER:
return self._to_dict_pattern1(round(self.values, 5))
elif self.property_type == PropertyType.CHECKBOX:
return self._to_dict_pattern1(self.values)
elif self.property_type == PropertyType.SELECT:
return self._to_dict_pattern2('name')
elif self.property_type == PropertyType.MULTI_SELECT:
values = self.get_multi_select_values()
return self._to_dict_pattern1(values)
elif self.property_type == PropertyType.RELATION:
return self._to_dict_relation()
def _to_dict_text(self):
return {
self.key: {
self.property_type: [
{
'text': {
'content': self.values
}
}
]
}
}
def _to_dict_relation(self):
return {
self.key: {
self.property_type: [
{
'id': self.get_page_id()
}
]
}
}
def _to_dict_pattern1(self, values):
return {
self.key: {
self.property_type: values
}
}
def _to_dict_pattern2(self, name):
return {
self.key: {
self.property_type: {
name: self.values
}
}
}
def get_multi_select_values(self):
values = []
if isinstance(self.values, str):
values.append({'name': self.values})
else:
for val in self.values:
values.append({'name': val})
return values
def get_page_id(self):
body = {
'filter': {
'property': 'Exp',
'text': {
'contains': self.values
}
}
}
url = f'{Config.notion_endpoint}/databases/{Config.database_id}/query'
response = requests.request('POST', url=url, headers=Config.headers, data=json.dumps(body))
return response.json()['results'][0]['id']to_notionメソッド
最後にNotionに連携する用のメソッドです。上記で用意したCellクラスをインスタンス化したものをリストで渡すことでNotionにAPI連携できるようになっています。
def to_notion(cells):
props = {}
for cell in cells:
props.update(cell.to_dict())
body = {
'parent': {
'database_id': Config.database_id
},
'properties': props,
}
url = f'{Config.notion_endpoint}/pages'
return requests.request('POST', url=url, headers=Config.headers, data=json.dumps(body))試しに動かしてみる
適当に作ったデータでデータベースにデータが登録できるか試してみます。
cells = [
Cell('Submit', properties, True),
Cell('Exp', properties, 'Exp001'),
Cell('Date', properties, datetime.datetime.now().strftime('%Y-%m-%d')),
Cell('CV', properties, 0.92),
Cell('Public LB', properties, 0.89),
Cell('Model Name', properties, 'LGBM'),
Cell('Preprocessing', properties, ['Normalization', 'Standardization']),
Cell('Memo', properties, 'MEMO')
]
response = to_notion(cells).json()
pprint(response)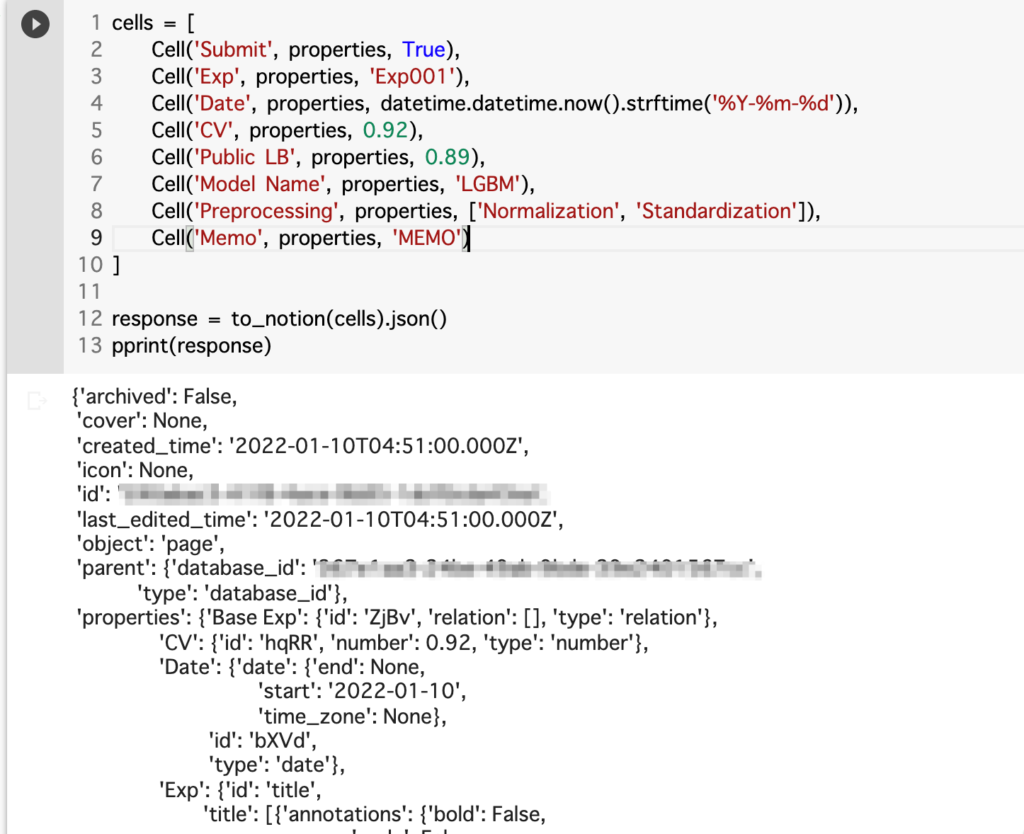
意図した通りにデータベースにレコードが追加されていますね!selectやmulti_selectのカラムに関しては、新しい選択肢が追加された場合には、何もしなくても選択肢を追加してくれます。

次にBase Expの動作を確認するために少し内容を変更して再度実行してみます。
cells = [
Cell('Submit', properties, False),
Cell('Exp', properties, 'Exp002'),
Cell('Date', properties, datetime.datetime.now().strftime('%Y-%m-%d')),
Cell('Base Exp', properties, 'Exp001'),
Cell('CV', properties, 0.90),
Cell('Public LB', properties, 0.81),
Cell('Model Name', properties, 'Catboost'),
Cell('Preprocessing', properties, ['Normalization']),
Cell('Memo', properties, 'Relation Sample')
]
response = to_notion(cells).json()
pprint(response)Base Expもうまく連携できていることがわかります。

コンペを想定して動かしてみる
最後にコンペを想定して動かしてみたいと思います。皆大好きTitanicのデータを使ってみたいと思います。
データ読み込み
train_df = pd.read_csv('train.csv')
print(train_df.shape)
display(train_df.head())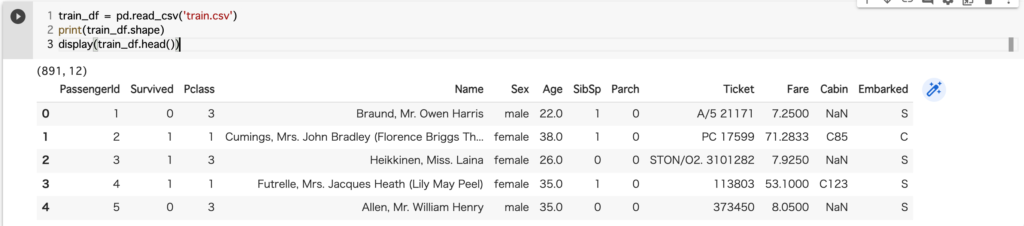
前処理
train_df['Sex'].replace(['male', 'female'], [0, 1], inplace=True)
train_df['Embarked'].fillna(('S'), inplace=True)
train_df['Embarked'] = train_df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int)
train_df['Fare'].fillna(np.mean(train_df['Fare']), inplace=True)
train_df['Age'].fillna(train_df['Age'].median(), inplace=True)
train_df['FamilySize'] = train_df['Parch'] + train_df['SibSp'] + 1
train_df['IsAlone'] = 0
train_df.loc[train_df['FamilySize']==1, 'IsAlone'] = 1データ分割など
# 不要カラム削除
delete_columns = ['Name', 'PassengerId', 'Ticket', 'Cabin']
train_df.drop(delete_columns, axis=1, inplace=True)
# 説明変数と目的変数をセット
train_y = train_df['Survived']
train_x = train_df.drop('Survived', axis=1)
# 学習用、検証用に分割
tr_x, va_x, tr_y, va_y = train_test_split(train_x, train_y, test_size=0.3, random_state=0, stratify=train_y)ロジスティック回帰
以下を実行すると「Accuracy: 0.69030」となります。
lr = LogisticRegression(penalty='l2', solver='sag', random_state=0)
lr.fit(tr_x, tr_y)
pred_y = lr.predict(va_x)
score = accuracy_score(va_y, pred_y)
print(f'Accuracy: {score:.5f}')Notionへの連携
cells = [
Cell('Exp', properties, 'Exp003'),
Cell('Date', properties, datetime.datetime.now().strftime('%Y-%m-%d')),
Cell('CV', properties, score),
Cell('Model Name', properties, 'LogisticRegression'),
Cell('Preprocessing', properties, ['fillna', 'FamilySize', 'IsAlone']),
]
response = to_notion(cells).json()
pprint(response)Preprocessingには適当に入れていますが、問題なく連携されていますね!

ランダムフォレストでの実行
rfc = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
rfc.fit(tr_x, tr_y)
pred_y = rfc.predict(va_x)
score = accuracy_score(va_y, pred_y)
print(f'Accuracy: {score:.5f}')
cells = [
Cell('Exp', properties, 'Exp004'),
Cell('Base Exp', properties, 'Exp004'),
Cell('Date', properties, datetime.datetime.now().strftime('%Y-%m-%d')),
Cell('CV', properties, score),
Cell('Model Name', properties, 'RandomForestClassifier'),
Cell('Preprocessing', properties, ['fillna', 'FamilySize', 'IsAlone']),
]
response = to_notion(cells).json()
pprint(response)
これにて確認は終了です!
試したけどできなかったこと
- 今回のコードには出てきていませんが、lossのグラフやfeature importanceなど画像を連携したいことは多々あると思います。NotionのAPIでは画像ファイルを送ることはできないため、これを実現することはできませんでした。ただし、画像のURLを連携して表示させることはできるみたいなので、Google Driveに画像を保存してそのURLを共有、みたいにすればできるかもしれません。
- 説明したコードでは、実験終了後にすべての情報をNotionに連携しています。ですが、最初に実験用のレコードを作成し、必要なタイミングでレコードを更新していく、といった利用方法もできると便利です。APIとしてはページの更新はできるみたいだったのですが、試したところエラーが出てしまいうまくいきませんでした。
まとめ
Notionはこれからも機能アップデートが頻繁にあると思うので、実験管理の用途でももっと便利になってくれると信じています。
Notionは実験管理以外にできることがたくさんあります。本も何冊か出ているので、読んでみるのも良いかもしれません。


(2025/07/01 02:26:13時点 Amazon調べ-詳細)





-320x180.png)
