こんにちは、@yshr10icです。
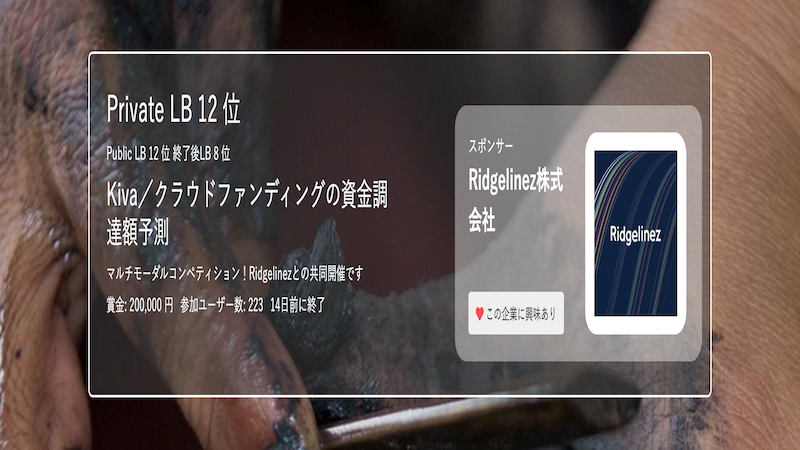
ProbSpaceで開催された「Kiva/クラウドファンディングの資金調達額予測」に参加し、12位で銀メダルを獲得することができました!

本記事では、コンペの振り返りをしたいと思います。
コンペの概要
今回のコンペの題材となっているKivaとは、インターネットを介してマイクロファイナンスを行うNPO機関で、小口融資を募りそれを取りまとめて発展途上国の個人事業主に融資する仕組みを提供しています。融資は一口25ドルからと、非常に少額から受け付けることができるのが特徴となっています。(参考:Wikipedia)
今回のコンペでは、2018,19年の過去2年の融資実績を訓練データとして、2020,21年の融資額(ドル)を予測するというものでした。説明変数としては、融資者の使用言語や融資者の説明(母国語、英語)、画像、国などになっており、テキストや画像、数値が混ざったマルチモーダルコンペとなっていました。
初めてのマルチモーダルコンペだったので、色々と苦戦しましたが、非常に勉強になるコンペでした!
解法
特徴量
各特徴量に対して行ったことは以下のとおりです。
- カテゴリデータ
- Target Encoding
- CatBoostの場合はcat_featuresとしてモデルに渡す
- テキストデータ
- textheroを用いたクレンジング
- 文章の長さや単語数などの基礎統計量
- TF-IDF -> TruncatedSVD
- CountVectorizer -> TruncatedSVD
- BERT(roberta-base) -> PCA
- Universal Sentence Encoder
- 融資者の説明の中から年齢および年の抽出
- 画像データ
- Swin Transformer -> PCA
- タグ
- One-Hotベクトル化
- タグ数のカウント
今回の特徴量の検討にはatmaCup#10のディスカッションをたくさん参考にさせてもらいました。

モデル
以下のモデルでのアンサンブル
- LightGBM
- CatBoost
- TabNet
後処理
後処理では、以下の2つを実施しました。
- テストデータと学習データで画像が重複しているレコードがあったため、同じ画像の場合は学習データの融資額で上書き
- 学習データの融資額が25〜10000の間の25の倍数となっていたため、予測値をクリッピングし25の倍数となるように変換
ディスカッションへの投稿
今までコンペに参加してきて、あまりディスカッションには投稿したことなかったのですが、今回はもっとコンペが盛り上がればいいなと思い、積極的にディスカッションに投稿するようにしました。
簡単なEDAやベースラインの作成などあまり有益な情報は書けませんでしたが、合計で5つのディスカッションを投稿しました。非常に多くの方からUpvoteいただけて非常に嬉しかったです!
おかげさまでディスカッションでもいくつかメダルを獲得し、ディスカッションのランキングで4位になることができました。1つのコンペで複数ディスカッションを書くだけでこのランキングになれてしまうので、ディスカッションがあまり活発でないことが分かりますね。

今後参加するコンペにおいてもなるべくディスカッションに投稿するようにし、有益な情報を提供できるようになりたいと思います。
参考にした本
特徴量生成などで参考にしました。コンペ参加するときには必須の本ですね。

こちらの本も特徴量の生成や、テキスト・画像の取り扱いなどで参考にしました。

(2025/07/03 21:57:29時点 Amazon調べ-詳細)
テキストデータのエンコーディングにBERTを使用したため、こちらの本で勉強しました。

(2025/07/03 23:54:35時点 Amazon調べ-詳細)
最後に
本コンペでは、Universal Sentence EncoderやTabNetなど今までに試したことなかった手法を試すことができました。ただ上位の方にはまだまだ及ばないのでもっと精進せねばと思いました!
また、本コンペの結果によりProbSpaceの総合ランキングで6位となることができました。今年の目標は5位以内に入ることなので、新しいコンペが始まりましたら積極的に参加したいと思います!







-320x180.png)